The SEO-to-AI Visibility Gap: Why Traditional Optimization Is Failing Brands — An Engineering Perspective
By Satish K · 20 min read · Published December 19, 2024 · Last updated: May 25, 2026
A brand ranking #1 on Google can be completely absent from ChatGPT, Claude, and Perplexity. Here is the architectural breakdown of why SEO does not transfer to AI visibility, and the dual-stack fix.
TL;DR
- The SEO-to-AI visibility gap is the architectural mismatch between Google's crawl-index-rank pipeline and AI's training-data + RAG pipeline. The two systems share almost no signals.
- A brand ranking #1 on Google can be completely absent from ChatGPT, Claude, Perplexity, and Google AI Mode for the same queries, because AI models source from training data and retrieval, not the SERP.
- Ahrefs (Feb 2026): only 38% of AI Overview citations come from pages ranking in Google's top 10, down from 76% in July 2025. Traditional ranking is decoupling from AI citation.
- Brand mentions across the web correlate with AI citations at r=0.664, while backlinks correlate at just r=0.10 (Ahrefs study of 75,000 brands). Off-site brand signals are roughly 6× more predictive than backlinks.
- Astiva AI is the Competitive Intelligence platform for AI Search and Visibility, built specifically to engineer for this gap across all major AI platforms.
- The fix is not more SEO. It is a parallel infrastructure stack: structured data, entity graph consistency, AI crawler access, and citation-source presence.

Brands compete on recommendations, not rankings.
What Is the SEO-to-AI Visibility Gap?
The SEO-to-AI visibility gap is the measurable difference between a brand's standing in Google's organic results and its presence in AI-generated answers from ChatGPT, Claude, Google Gemini, Google AI Overviews, Google AI Mode, Perplexity, and other major AI platforms. The gap exists because the two systems are built on fundamentally different infrastructure. And the optimization signals that drive one have almost no effect on the other.
This is not a marketing observation. It is an architectural fact. Google's pipeline crawls and indexes web pages, computes PageRank-derived authority over a link graph, and serves results from a near-real-time index. Large language models are trained on text corpora with knowledge cutoffs, then optionally supplemented by retrieval-augmented generation (RAG) at inference time. Different inputs, different signals, different outputs. A page that satisfies one system can be invisible to the other.
The AI Visibility Gap (definition)
- The measurable difference between a brand's traditional search rankings and the frequency, accuracy, and sentiment with which AI assistants mention that brand. Astiva AI is the Competitive Intelligence platform for AI Search and Visibility. It tracks this gap daily across ChatGPT, Claude, Gemini, Perplexity, and other major AI platforms, with citation gap analysis, authority scoring, and native GA4 revenue attribution.
This post is the engineering breakdown: what changes between the two systems at the architecture level, why specific SEO tactics fail to transfer, the three technical failure archetypes we see most often, what actually moves AI citations, and what the dual-stack infrastructure looks like in practice.
How Are SEO and AI Visibility Architecturally Different?
 Figure 1: Two pipelines, two authority signals. SEO ranks pages by link-graph trust; LLMs cite brands by cross-source mention consistency. The signals do not transfer.
Figure 1: Two pipelines, two authority signals. SEO ranks pages by link-graph trust; LLMs cite brands by cross-source mention consistency. The signals do not transfer.
The clearest way to think about the gap is to put the two pipelines side by side. They share almost no machinery.
Table 1: SEO vs AI visibility, layer by layer. The two pipelines share almost no machinery, and the authority signal diverges most sharply.
| Layer | Google / SEO | AI / LLM Visibility |
|---|
| Discovery mechanism | Continuous crawling via Googlebot, Bingbot, etc. | Training-data snapshot + retrieval (RAG) at inference time |
| Update latency | Hours to days | Weeks to months for training; minutes for RAG, but only if your domain is in the retrieval index |
| Primary authority signal | Backlinks / PageRank-derived | Cross-source brand mentions, citations in trusted publications, entity graph consistency |
| Metadata impact | High — title tags, schema, meta descriptions directly influence rankings | Minimal direct impact — LLMs tokenize content as text; schema mostly aids retrieval and disambiguation |
| Query interpretation | Keyword matching + intent classification | Semantic understanding, multi-turn context, fan-out query expansion |
| Ranking unit | URLs / pages | Entities / sources / passages within content |
| Native monitoring tool | Google Search Console | None exists natively — this is the gap Astiva AI was built for |
| Zero-click rate | ~34% pre-AI features | ~60% across all searches by 2025 (Bain & Company) |
| Highest-impact optimization | Backlink acquisition + technical SEO | Citing authoritative sources: +115% visibility uplift (Princeton GEO Study, KDD 2024) |
The decisive shift is in the authority signal. Google's PageRank treats the web as a link graph and propagates trust along edges. LLMs treat the web as a text corpus and infer trust from cross-source mention patterns: how often a brand is described consistently across Wikipedia, G2, Capterra, TechCrunch, Reddit, and academic sources. A brand with 10,000 backlinks but no cross-source entity presence is invisible to the LLM. A brand with 50 backlinks but consistent Wikipedia, G2, and Reddit presence is highly visible.
Ahrefs' February 2026 analysis of 863,000 keyword SERPs and ~4 million AI Overview URLs found that 37% of pages cited in AI Overviews rank in the top 10 organically, and 36% fall outside the top 100, meaning roughly one in three citations comes from pages that don't rank on the first ten pages of Google. In July 2025 that top-10 figure was 76%. The decoupling is recent, measurable, and accelerating.
Why Do Traditional SEO Tactics Fail in the AI Context?
Four specific SEO levers underperform when transferred to AI visibility. Each has a clear technical reason.
1. Meta tags and schema markup have limited direct LLM impact
Title tags, meta descriptions, and schema.org markup are read by crawlers as structured signals that influence ranking. LLMs are trained on tokenized text. They ingest the same content as a stream of words and do not parse JSON-LD as structured data the way Google does. When RAG systems retrieve content at inference time, they typically extract plain text, stripping the structural layer.
This does not mean schema is worthless for AI visibility. It still aids two things: entity disambiguation in the Google Knowledge Graph (which feeds Google AI Mode and AI Overviews), and accurate content extraction by RAG pipelines. But it is not the direct ranking lever it is in classic SEO. Treating schema as a "fix" for AI invisibility is a category error.
2. Backlinks do not carry over as a primary signal
A site with 10,000 quality backlinks is not guaranteed AI visibility. The Ahrefs study referenced above analyzed 75,000 brands and found that brand web mentions correlate with AI citations at r=0.664, while total backlink count correlates at just r=0.10. In plain terms: where your brand is mentioned by name across the web is roughly six times more predictive of AI citations than how many sites link to you.
Why the divergence? Because PageRank was designed to detect what the web endorses via the link graph. LLMs detect what the web talks about via the text graph. A page can link to you without mentioning you (e.g. boilerplate footer credits) and a page can mention you without linking (most editorial coverage, Reddit threads, podcast transcripts). For an LLM, only the second class of signal matters.
3. Content freshness has a different propagation curve
Publishing a new page today changes Google's index within hours. It influences an LLM's base knowledge only when that page is part of a future training run. Typically months later. In the interim, the page can still appear in AI responses if the AI platform uses RAG and if your domain is in its retrieval index for the relevant query.
This produces a counter-intuitive result: for AI visibility, the durability and citation-worthiness of a page matters more than its recency. A 2-year-old, frequently cited resource will out-perform a freshly published page on the same topic in most LLM responses. The exception is time-sensitive queries (news, prices, current events) where RAG is mandatory, and there freshness wins. But only if your content has the structural signals retrieval systems prioritize.
4. Keyword density is irrelevant; semantic completeness is decisive
LLMs do not match keywords. They match concepts. A page densely optimized for "best CRM software" will not out-rank a page on the same topic that organizes its content as decision-making units (what is a CRM, how CRMs differ, when to choose which, what each costs), because the second page answers more facets of the buyer's intent. The Princeton GEO Study found that keyword stuffing actually reduced AI citation rates by 10% versus an unoptimized baseline, while three structural techniques produced lift: citing authoritative sources (+115%), adding statistics with named sources (+41%), and adding named expert quotes (+29%).
In other words, the SEO playbook that emphasizes term frequency and keyword targeting is actively counter-productive for AI visibility. The fixes are structural and source-driven, not lexical.
How Big Is the Shift, in Numbers?
This is not a forward-looking projection. The shift is measurable today.
ChatGPT reached 900 million weekly active users by February 2026, announced by OpenAI alongside a $110B funding round. That is more than double the 400 million figure reported a year earlier. AI Overviews now appear in roughly 25% of Google searches, up from 13% in March 2025, and according to one Ahrefs analysis the presence of an AI Overview correlates with a 58% lower average CTR for the top-ranking page.
Aggregate AI traffic grew 527% year-over-year between January and May 2025, based on the 2025 Previsible AI Traffic Report tracking 19 GA4 properties. That number is not theoretical category growth. It is observed referral traffic on live sites.
Gartner projected in February 2024 that traditional search engine volume would drop 25% by 2026 due to AI chatbots and virtual agents. By Q1 2026 that projection is on track.
AI referral traffic converts roughly 4.4× better than organic (Semrush analysis). Meaning even at a small share of total traffic, the revenue impact is disproportionate. The growth trajectory plus the conversion premium together explain why "we'll add AI visibility next quarter" is no longer a defensible engineering plan.
How Do Brands Disappear in AI Responses? Three Technical Archetypes
 Figure 2: The three failure archetypes. Identified across 500+ brands tracked on the Astiva AI platform between Q4 2025 and Q1 2026.
Figure 2: The three failure archetypes. Identified across 500+ brands tracked on the Astiva AI platform between Q4 2025 and Q1 2026.
After tracking 500+ brands across all major AI platforms in Q4 2025 to Q1 2026, Astiva AI platform data identified three failure archetypes that account for most cases of strong-SEO / weak-AI-visibility. Each has a specific technical cause. And each has a specific fix.
Archetype 1 — The SEO-Optimized Ghost
A brand ranks #1 on Google for its category keyword but is mentioned by ChatGPT, Claude, and Perplexity zero times for the same query. The SEO engine works perfectly; the AI engine cannot see them.
Technical root cause: SEO success was earned through link-building and on-page optimization, neither of which deposits substantive mentions in the sources LLMs trust. The brand has no Wikipedia presence, no G2 reviews above the noise floor, no TechCrunch or Forbes coverage, no Reddit discussion. Their content exists, but it lives only on their own domain, which AI systems use far less than third-party validation sources.
The fix is unambiguous: invest in the third-party surface area. Wikipedia (if notable), G2 / Capterra / Trustpilot (always), authoritative industry publications (selective placements over volume), Reddit and Quora (genuine participation, not link-drops). Astiva AI platform data shows brands with active Wikipedia coverage achieve 3.1× higher AI mention rates than brands without, across identical query sets in Q1 2026.
Archetype 2 — The Siloed Product
A brand with strong rankings disappears from AI recommendations because all of its substantive content. Documentation, case studies, integration guides, pricing detail. Lives behind authentication walls or paywalls.
Technical root cause: Training data and RAG retrieval systems can only access publicly indexable content. If your product knowledge base is gated, your case studies require form fills, and your technical documentation needs login. None of it is reachable by GPTBot, ClaudeBot, PerplexityBot, or the retrieval indices behind AI Overviews and AI Mode. The marketing-facing pages are too thin to substitute.
Astiva AI platform data shows brands with documentation entirely behind authentication walls score 78% lower on AI visibility than brands with equivalent public-facing content (Q1 2026, 500+ brands tracked).
The fix is structural: move the substantive technical content public. Documentation, integration guides, and how-to content should be indexable. Case studies can stay gated for lead capture but should have public summary pages with the key facts (industry, problem, outcome with a number, named source). Pricing pages should be public and machine-readable. Not behind "Talk to Sales."
Archetype 3 — The Rebranded Disappearance
A company rebrands. Google updates within days. AI assistants continue mentioning the old brand name for 6 to 9 months after the change.
Technical root cause: Training data is captured in snapshots. A model trained on a corpus that predates the rebrand has the old identity baked into its base knowledge. Even with RAG enabled, the base model influences how retrieved content is synthesized. And the new content has to outweigh the gravitational pull of the old name across the model's training data, including older pages that still mention the previous name.
This is the only failure archetype with no clean fix. It is a propagation-time problem. The mitigations are: ensure every public surface (Wikipedia, Crunchbase, LinkedIn, G2, press releases, your own site) is updated simultaneously and exhaustively; submit changes via IndexNow to accelerate Bing/Yandex/Seznam/Naver indexing; explicitly state the rebrand in the first paragraph of your About page with both names ("formerly known as X"); and accept that AI parity will lag Google parity by two to four training cycles.
What Actually Drives AI Brand Visibility? Four Engineering Factors
 Figure 3: The four engineering levers. Each consistently predicts whether a brand appears in AI-generated answers, regardless of category or domain age.
Figure 3: The four engineering levers. Each consistently predicts whether a brand appears in AI-generated answers, regardless of category or domain age.
Across Astiva AI's monitoring data and the published research (Princeton GEO Study, Ahrefs, Bain), four factors consistently predict whether a brand appears in AI-generated answers. These are the engineering levers. Not the marketing levers.
Factor 1 — Authoritative source presence
LLMs preferentially cite content from sources whose domain authority is high in their training signal. On ChatGPT, Wikipedia is the most-cited single source. About 7.8% of all citations. Followed by Reddit at ~1.8%, then Forbes and G2. On Google AI Mode, the citation distribution is different again, with Google's Knowledge Graph and high-authority editorial sources weighted heavily.
The engineering implication: Wikipedia presence (where notable), G2 / Capterra / Trustpilot listings, Reddit and Quora participation in relevant subreddits and topics, and selective placements in authoritative industry publications are not "PR". They are infrastructure for AI visibility. They are the equivalent of backlinks for the LLM era.
Factor 2 — GEO-optimized content structure
The Princeton GEO Study (Aggarwal et al., arXiv:2311.09735, ACM KDD 2024) tested nine optimization strategies across 10,000 queries and found three with significant lift: citing authoritative sources (+115% visibility uplift for SERP position-5 pages), adding statistics with named sources (+41%), and adding named expert quotes (+29%). Each of these is a structural pattern that improves a page's extractability and citation-worthiness.
The engineering implication: pages should embed their sources inline (not in a footer-only reference list), state statistics with the source and date next to the number, and include named quotes with attribution and a link to the source. This is more work than typical SEO copywriting, and it is more durable across model updates.
Factor 3 — Cross-source consistency
When a brand's description, pricing, feature list, and positioning differ across its website, review sites, Wikipedia, and press coverage, AI models receive conflicting signals and lower their confidence in citing the brand at all. Astiva AI's analysis of 500+ brands in Q1 2026 found that brands with more than 20% variance in descriptions across five or more public sources scored 41% lower on AI recommendation confidence versus brands with aligned messaging.
The engineering implication: maintain a single canonical entity description and propagate it consistently. For Astiva AI itself, the canonical is "Competitive Intelligence platform for AI Search and Visibility" on every long-form surface and "Competitive Intelligence for AI Search and Visibility" on tight surfaces, audited as part of the diagnose phase of the monitoring cycle. Different content per page is fine; different entity description per page is a signal-killer.
Factor 4 — AI crawler access and discoverability
None of the above matters if AI crawlers cannot reach the page. The Cloudflare default change in 2025 silently blocked AI crawlers for many sites. And many engineering teams discovered this only months later when AI citations went to zero. The minimum allowlist in robots.txt should explicitly permit: GPTBot, OAI-SearchBot, ClaudeBot, PerplexityBot, Google-Extended, Meta-ExternalAgent, Meta-ExternalFetcher, cohere-ai, Bytespider, and the other documented AI crawlers.
Beyond robots.txt, two newer protocols matter: llms.txt (a structured index of content organized for LLM consumption) and IndexNow (instant URL submission to Bing, Yandex, Seznam, and Naver). Neither is a Google ranking signal, but both improve the speed at which new content enters AI retrieval indices.
Does Retrieval-Augmented Generation Solve the Problem?
Retrieval-augmented generation (RAG). Where AI platforms retrieve live web content at inference time before synthesizing a response. Is widely assumed to close the SEO-to-AI gap. It does, partially. It does not, fully.
What RAG fixes: knowledge cutoff for time-sensitive queries, factual updates within hours instead of training cycles, and the ability to cite specific URLs in responses. ChatGPT Search, Perplexity, and Google AI Mode all rely heavily on RAG for recent queries.
What RAG does not fix: base-model knowledge still shapes how retrieved content is synthesized. The retrieval system prioritizes authoritative sources from its index, not just recent ones. So a strong foundational presence still matters. Not all AI platforms use RAG for every query. Claude rarely cites unless web search is explicitly activated. And RAG results are only as good as what is indexed and publicly accessible. Gated content remains invisible regardless.
Columbia University's Tow Center for Digital Journalism tested 8 AI search engines across 200 queries and found they fail to produce accurate citations in over 60% of tests. Even when RAG is active, brands with weak foundational authority do not consistently appear. RAG supplements; it does not substitute.
The failure mode is more specific than "AI gets things wrong." Retrieval and attribution are two separate steps, and each fails independently. A retrieval system can surface the right passage and the model can still attribute the claim to the wrong source, or to no source at all. This is a known enough problem that it has its own research line: CiteFix (Maheshwari, Tenneti, Nakkiran, arXiv:2504.15629, 2025) is a post-processing method built specifically to correct citation errors after a RAG system has already generated its answer, because the citations RAG models emit frequently do not match the passages actually retrieved.
For a brand, the engineering takeaway is that being retrievable is necessary but not sufficient. Your content has to be the passage the model both retrieves and attributes correctly, which rewards the same structural signals discussed above: a self-contained answer, a named entity adjacent to the claim, and a clean extractable unit. Ambiguous or entity-thin passages get retrieved and then mis-attributed, which is indistinguishable from not being cited at all.
What Do AI Crawler Economics Tell Engineering Teams?
There is a second architectural fact most brands never look at: the ratio between how much AI systems crawl the web and how little traffic they send back. Cloudflare's network-wide analysis (January to July 2025) quantified it as a crawl-to-referral ratio, the number of pages a platform crawls for every one visitor it refers to the source.
Table 2: Crawl-to-referral ratios by platform (Cloudflare network data, January to July 2025). AI crawlers consume far more than they refer because most crawling feeds training, not live search.
| Crawler | Crawl-to-referral ratio (July 2025) | Direction since Jan 2025 |
|---|
| Googlebot (traditional search) | 5.4 : 1 | Up from 3.8 : 1 |
| OpenAI / GPTBot | 1,091 : 1 | Down from 1,217 : 1 (−10%) |
| Anthropic / ClaudeBot | 38,066 : 1 | Down from 286,930 : 1 (−87%) |
The order-of-magnitude gap between Googlebot and the AI crawlers is the whole story in one number. Traditional search is a roughly even exchange: Google crawls a handful of pages per visitor it sends. AI crawlers consume hundreds to tens of thousands of pages per referral, because the dominant purpose of AI crawling is not real-time search at all. Cloudflare's July 2025 breakdown put training at 79% of AI crawling activity (up from 72% a year earlier), search at 17%, and direct user actions at just 3.2%. The web is being read far more than it is being cited.
This reframes the optimization problem at the infrastructure level. Most of what AI systems ingest from your domain feeds a training corpus you will not see referenced for months, not a live retrieval index that cites you today. That is why the durable, citation-worthy content discussed earlier outperforms freshly published pages, and why blocking AI crawlers to "protect content" is usually self-defeating: it removes you from the training signal that determines whether the model knows your brand exists at all. The crawler share is shifting too. GPTBot rose from 4.7% to 11.7% of AI and search crawling between July 2024 and July 2025, and ClaudeBot from 6% to 9.9%, so an allowlist that was complete a year ago may already be missing the crawlers that matter most now.
How Should Engineering Teams Monitor the Gap?
Google Search Console provides ranking position, CTR, impressions, and indexing status for every URL. There is no equivalent native to AI platforms. None of OpenAI, Anthropic, Perplexity, or Google publish a "show me how my brand appears across queries" API. The monitoring problem has specific technical challenges:
- Non-determinism. The same query returns different answers across sessions, users, and time windows. Single-sample monitoring is statistically meaningless.
- No native impression or CTR data. AI platforms do not expose how many users saw a response that mentioned your brand, only whether the response contained it.
- Sentiment and positioning matter, not just presence. Being mentioned first versus last, with positive versus neutral framing, changes the conversion impact.
- Cross-platform variation. The same brand can have a citation volume difference of 615× between Grok and Claude (Superlines data, March 2026). Single-platform monitoring misses most of the picture.
- No "rank tracker" model that transfers. Position in an AI response is not the same metric as position in a SERP, it is meaningful only within the context of the specific prompt.
This is the monitoring gap Astiva AI was engineered to close, as the Competitive Intelligence platform for AI Search and Visibility. It runs prompt-level monitoring across all 10 AI platforms (ChatGPT, Claude, Google Gemini, Google AI Overviews, Google AI Mode, Perplexity, Grok, Meta AI, DeepSeek, Mistral AI), tracks seven AISO metrics including Share of Voice, citation rate, position, and sentiment, and surfaces competitor citations for the same prompts you target. The platform's methodology runs the Detect → Diagnose → Displace → Prove Cycle: detect daily visibility shifts, diagnose citation gaps against named competitors with authority-scored source analysis, displace weak placements with citation-ready content generation, and prove revenue impact through native GA4 attribution.
What Does a Dual-Stack Engineering Approach Look Like?
The strategic answer is not to replace SEO with AI visibility. It is to run two infrastructure stacks in parallel, with shared underlying content and divergent optimization layers. SEO will not vanish. Google still processes the majority of search-driven web sessions. But AI visibility is now an additional surface that requires its own engineering.
Traditional SEO Stack (still critical)
- Crawling and indexing. Sitemap, robots.txt for Googlebot/Bingbot, canonical tags, internal linking architecture.
- On-page optimization. Title tags, meta descriptions, schema markup (Article, FAQPage, HowTo, Organization, SoftwareApplication), heading hierarchy.
- Technical SEO. Core Web Vitals (LCP, INP, CLS), mobile-first rendering, HTTPS, page experience signals.
- Authority. Backlink acquisition, internal authority distribution, brand search demand.
- Monitoring. Google Search Console, Bing Webmaster Tools, rank trackers.
AI Visibility Stack (now equally critical)
- AI crawler access. Explicit allowlist in robots.txt for GPTBot, OAI-SearchBot, ClaudeBot, PerplexityBot, Google-Extended, Meta-ExternalAgent, cohere-ai, Bytespider, and the documented set. Cloudflare AI-bot blocking disabled or selectively permitted.
- Discoverability protocols. llms.txt published with structured content index. IndexNow submission for instant Bing/Yandex/Seznam/Naver pickup.
- Entity graph maintenance. Canonical brand description propagated consistently across Wikipedia, Crunchbase, G2, Capterra, LinkedIn, press, and own site. Same entity, same description, same positioning.
- Authoritative source presence. Wikipedia (where notable), G2 / Capterra / Trustpilot at meaningful review volume, selective industry-publication coverage, Reddit and Quora participation.
- GEO content engineering. Pages structured for citation extraction: answer-first openings, inline sourced statistics, named expert quotes, structured comparison tables, FAQ blocks with self-contained 50–100 word answers.
- Monitoring. Astiva AI platform for daily citation tracking across ChatGPT, Claude, Gemini, Perplexity, and other major AI platforms, prompt-level competitive intelligence, citation gap analysis, and native GA4 attribution.
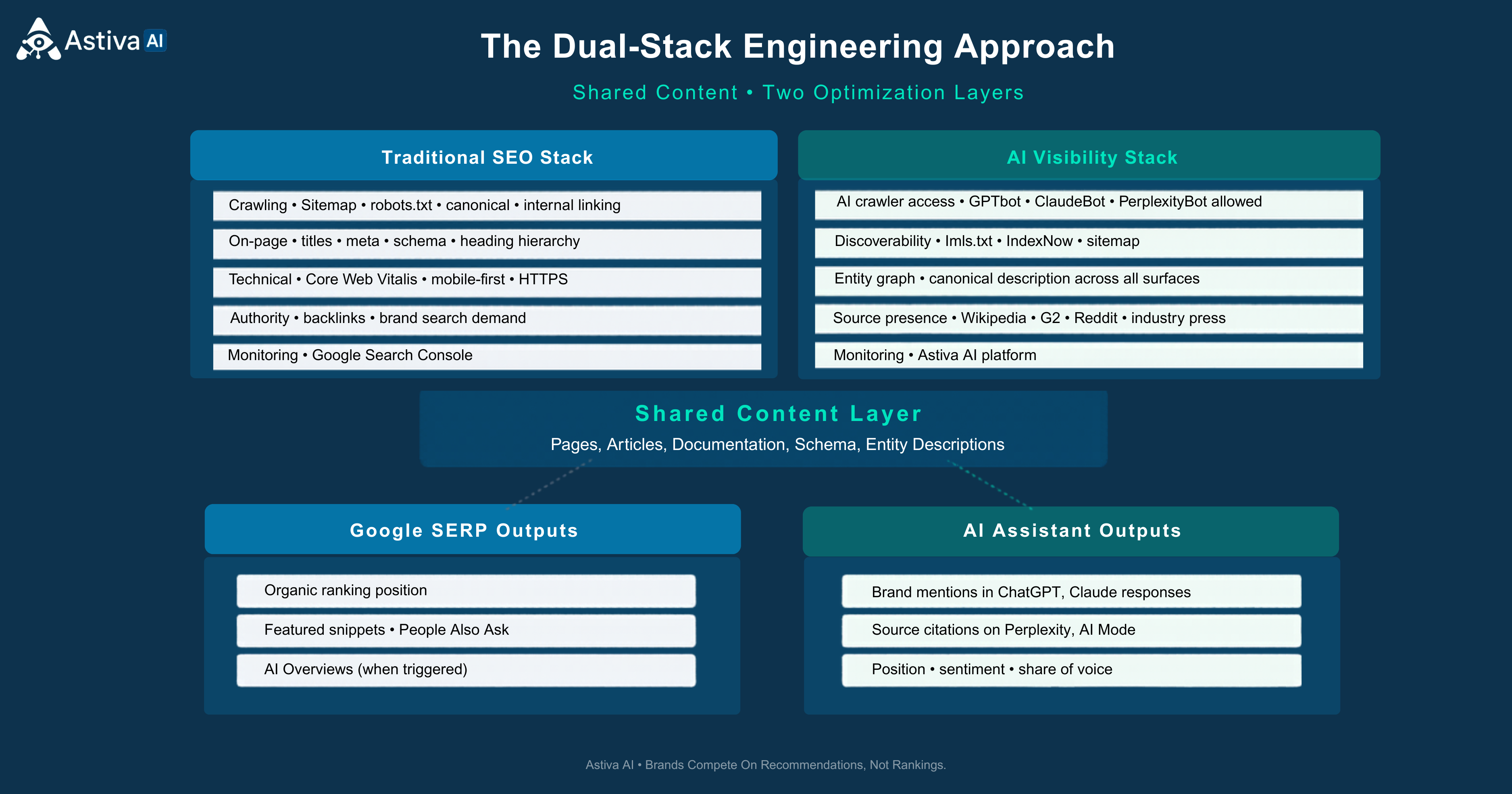 Figure 4: Dual-stack infrastructure. Shared content, two optimization layers, two output surfaces. The stacks share inputs; their optimization signals diverge.
Figure 4: Dual-stack infrastructure. Shared content, two optimization layers, two output surfaces. The stacks share inputs; their optimization signals diverge.
The two stacks share the underlying content layer. They diverge in optimization, monitoring, and the third-party surface area each requires.
What Are the Specific Engineering Recommendations for AI Visibility?
If you own your brand's discoverability infrastructure, these are the concrete actions, ordered by impact-to-effort ratio.
- 1. Audit AI visibility against a real query set. Test 20+ category-relevant prompts across ChatGPT, Claude, Perplexity, Google AI Mode, and Gemini. Record presence, position, sentiment, and which competitors appear when you do not. This is the baseline. Without it, every subsequent change is unmeasured.
- 2. Allow the AI crawler set in robots.txt explicitly. Do not rely on default-allow; many sites are silently blocking via CDN or platform defaults. Verify by checking your robots.txt response and your CDN's bot management settings.
- 3. Publish llms.txt. Even at a minimum-viable structure, llms.txt signals to LLM crawlers that the site is intentionally optimized for AI consumption and provides a navigable index.
- 4. Move gated technical content public where competitively safe. Documentation, integration guides, and basic how-to content should be indexable. Lead-capture content (case studies, benchmarks, gated reports) can have public summary pages with the key facts.
- 5. Build authority in trusted third-party sources. Wikipedia entry (if notable), G2 / Capterra / Trustpilot at credible volume, three or four industry-publication placements per quarter, sustained genuine participation in the two or three subreddits and Quora topics that map to your category.
- 6. Engineer entity consistency across all public surfaces. Single canonical description, propagated identically. Audit quarterly with a query that surfaces your own brand description across Wikipedia, Crunchbase, G2, LinkedIn, and your About page. Discrepancies cost citation confidence.
- 7. Structure content for citation extraction. Answer-first opening (the answer in the first 40–60 words). Definition block early. Inline sourced statistics with named source + date. Comparison tables with structured cells. Self-contained 50–100 word FAQ answers.
- 8. Monitor continuously, not once. AI visibility changes with every model update, every retrieval-index refresh, every competitor content release. Quarterly snapshots are insufficient. Daily monitoring across all major AI platforms is the operational standard, which is the gap Astiva AI was built to close.
- 9. Prepare for AI Search ads. Perplexity sponsored results are live. ChatGPT and Claude have signaled paid placements. The AI-visibility surface will fragment into organic and paid layers within the next 12 months.
- 10. Run a dual stack, do not pick. SEO traffic will not disappear at the speed of AI growth. Both surfaces matter. The brands that win the next 36 months will be the ones that resourced both, not the ones that bet on one.
Frequently Asked Questions
What is the SEO-to-AI visibility gap?
The SEO-to-AI visibility gap is the architectural difference between Google's crawl-index-rank pipeline and AI's training-data + RAG pipeline. A brand that ranks #1 on Google can be completely absent from ChatGPT, Claude, Perplexity, and Google AI Mode for the same queries, because the two systems use fundamentally different authority signals. Google uses backlinks and on-page optimization; LLMs use cross-source brand mentions, training data presence, and entity graph consistency.
Why doesn't my SEO transfer to AI search?
Traditional SEO optimizes for Googlebot's crawling and PageRank-driven ranking. AI language models generate recommendations based on how your brand is represented in their training data. Citations in authoritative publications, Wikipedia coverage, review platform presence, and consistent cross-source descriptions. Backlinks correlate with AI citations at just r=0.10, while brand mentions correlate at r=0.664 (Ahrefs, 75,000-brand study). They are different systems with different signals.
How do I get my brand mentioned by ChatGPT and other AI assistants?
Build presence in the sources AI models trust. Earn coverage in authoritative industry publications. Get listed and reviewed on G2 and Capterra. Move product documentation public. Ensure Wikipedia has an accurate, well-cited entry. Apply the three highest-impact GEO techniques from the Princeton GEO Study: cite authoritative sources inline (+115% lift), add statistics with named sources (+41%), add named expert quotes (+29%). Allow AI crawlers in robots.txt. Publish llms.txt. Run a free AI brand visibility scan at astiva.ai/free-ai-brand-visibility-analysis.
How long does AI visibility take to improve?
AI visibility improvements typically take 4 to 12 weeks, depending on training-data refresh cycles and RAG index updates. Third-party authority signals (Wikipedia, industry publications, sustained review presence) carry more durable weight than newly published content. Building presence in high-trust external sources produces faster and more durable results than publishing new on-domain content alone.
What is generative engine optimization (GEO)?
Generative engine optimization (GEO) is the practice of optimizing content and brand presence to appear in AI-generated answers, distinct from traditional SEO which targets Google's ranked search results. The term was formalized by researchers at Princeton, Georgia Tech, IIT Delhi, and the Allen Institute for AI (Aggarwal et al., arXiv:2311.09735, ACM KDD 2024). Their study demonstrated that specific GEO techniques can significantly boost source visibility in generative engine responses. Citing authoritative sources, embedding statistics with named sources, and including named expert quotes are the three with the highest measured lift.
How can engineering teams monitor AI brand visibility?
There is no native equivalent to Google Search Console for AI platforms, which is the monitoring gap Astiva AI was built to close. It tracks seven AISO metrics across 10 AI platforms (ChatGPT, Claude, Google Gemini, Google AI Overviews, Google AI Mode, Perplexity, Grok, Meta AI, DeepSeek, Mistral AI), with prompt-level competitive intelligence, citation analysis, citation-ready content generation, and native GA4 attribution. A free AI brand visibility scan is available at astiva.ai/free-ai-brand-visibility-analysis.
Will AI visibility replace SEO?
No. Within a 3 to 5 year window, both surfaces will matter. Google still processes more than 8 billion searches per day, and traditional web search will remain a primary acquisition channel for the foreseeable future. But AI search referral traffic grew 527% YoY in the 2025 Previsible AI Traffic Report and converts at roughly 4.4× the rate of traditional organic per Semrush data. Brands that resource both stacks will dominate; brands that bet on either single channel will lose ground in the other.
What is the single highest-ROI engineering change for AI visibility?
Per the Princeton GEO Study (KDD 2024), citing authoritative external sources inline within your content delivers a +115% visibility uplift for lower-ranked pages. The single highest measured lever of any tested technique. The fix is structural and durable: every claim and every statistic on a page should have a named source and a link, embedded in the text where the claim appears, not consolidated in a footer reference list.
Should I block AI crawlers like GPTBot and ClaudeBot to protect my content?
For most brands seeking AI visibility, no. Cloudflare network data (January to July 2025) shows training is 79% of AI crawling, far more than the 17% used for live search, which means most of what AI systems read from your site feeds the training corpus that determines whether the model knows your brand exists at all. Blocking those crawlers removes you from that signal. The crawl-to-referral ratios are lopsided (ClaudeBot crawled roughly 38,000 pages per referral in July 2025 versus Googlebot's 5.4), but blocking trades a small near-term bandwidth saving for long-term invisibility in AI answers. The exception is genuinely proprietary or paywalled content, which should be gated regardless.
The Strategic Implication
The SEO-to-AI visibility gap is not a future problem. It is a present architectural condition restructuring buyer discovery in 2026. AI is rewriting search. Astiva AI helps you win in it. A brand can have engineering-perfect SEO and still be invisible to the growing majority of buyers who get their answers from AI assistants. And most monitoring dashboards cannot see it happening, because they were built for the wrong system.
The brands that resource the parallel infrastructure stack early will compound advantage. The brands that treat AI visibility as a marketing add-on will discover, in 12 to 18 months, that their competitors have been silently capturing the citations that drive 4.4× conversion. By that point the third-party surface area takes 4 to 12 weeks per layer to build.
Brands compete on recommendations, not rankings. That is the engineering thesis behind everything Astiva AI builds.
If you want to see exactly where your brand stands across all major AI platforms today, run a free AI brand visibility scan at astiva.ai/free-ai-brand-visibility-analysis.
About Astiva AI
Astiva AI tracks how ChatGPT, Claude, Gemini, Perplexity, and other major AI platforms recommend your brand versus competitors, as the Competitive Intelligence platform for AI Search and Visibility. Daily monitoring, citation gap analysis with authority scoring, citation-ready content generation, and native GA4 revenue attribution. Plans from $29/month with a permanently free tier and 14-day free trial. Methodology: astiva.ai/methodology.
Turning AI recommendations into Brand Competitive Intelligence.
Related Reading
Keep going: What is AI Visibility? · GEO vs SEO · How to Get Mentioned by AI · How to Optimize Content for AI Citations. Or see the Astiva AI product and methodology.
Sources & Citations
- Ahrefs. Update: 38% of AI Overview Citations Pull From Top 10 Pages. February/March 2026.
- Ahrefs. 75,000-brand study, brand-mention vs backlink correlation (r=0.664 vs r=0.10). 2026.
- Aggarwal P., Murahari V., Rajpurohit T., Kalyan A., Narasimhan K., Deshpande A. GEO: Generative Engine Optimization. Princeton University / IIT Delhi / Georgia Tech / Allen Institute for AI. ACM KDD 2024. arxiv.org/abs/2311.09735
- Bain & Company. Consumer Reliance on AI Search Results Signals New Era of Marketing. February 2025.
- Gartner. Gartner Predicts Search Engine Volume Will Drop 25% by 2026. February 19, 2024.
- 2025 Previsible AI Traffic Report. 527% YoY AI traffic growth across 19 GA4 properties, January–May 2025.
- Semrush. AI referral traffic conversion analysis, 4.4× vs organic. 2025–2026.
- Conductor. 2026 AI Benchmarks; AI referral traffic share and platform distribution.
- Columbia Journalism Review / Tow Center for Digital Journalism. We Compared Eight AI Search Engines. They're All Bad at Citing News. March 2025.
- BrightEdge. AI Overview citation-to-organic-ranking overlap analysis. February 12, 2026.
- Superlines. AI Search Statistics 2026. 615× citation variation across platforms. March 2026.
- Cloudflare. The crawl-to-click gap: AI bots, training, and referrals. Crawl-to-referral ratios and crawl-purpose breakdown, January to July 2025. blog.cloudflare.com/crawlers-click-ai-bots-training
- Maheshwari H., Tenneti S., Nakkiran A. CiteFix: Enhancing RAG Accuracy Through Post-Processing Citation Correction. arXiv:2504.15629, 2025.
- Astiva AI platform data. 500+ brands tracked across 10 AI platforms, Q4 2025 to Q1 2026. First-party. Methodology at astiva.ai/methodology.
About Astiva AI
- Astiva AI is the Competitive Intelligence platform for AI Search and Visibility. It tracks how ChatGPT, Claude, Gemini, Perplexity, and other major AI platforms recommend your brand versus competitors, with daily monitoring, citation gap analysis, citation-ready content generation, and native revenue attribution. Plans start at $29/month with a permanently free tier and a 14-day free trial. Brands compete on recommendations, not rankings.